jaeger环境部署
Jaeger架构
Jaeger 既可以部署为一体式二进制文件 (ALL IN ONE),其中所有 Jaeger 后端组件都运行在单个进程中,也可以部署为可扩展的分布式系统 (高可用架构)
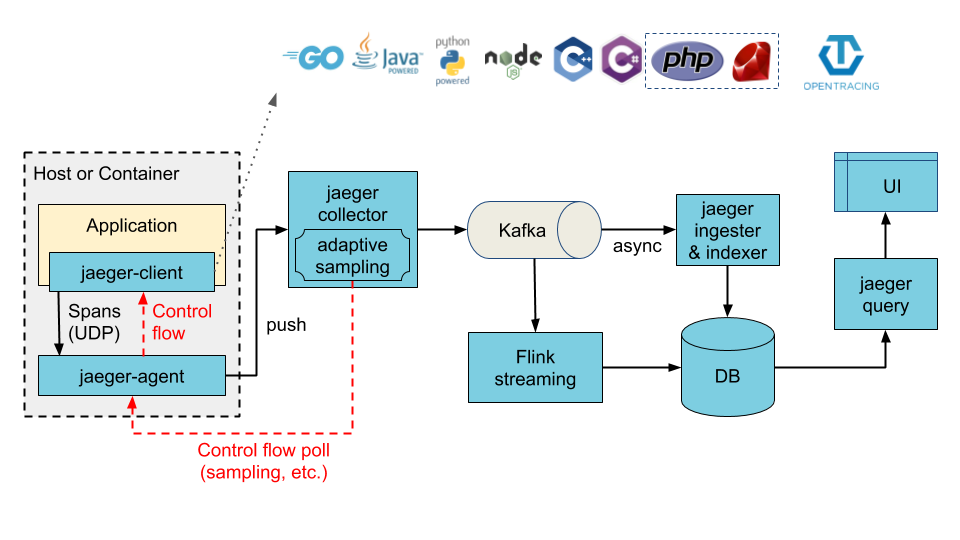
主要有以下几个组件:
- Jaeger Client : OpenTracing API 的具体语言实现。它们可以用来为各种现有开源框架提供分布式追踪工具。
- Jaeger Agent : Jaeger 代理是一个网络守护进程,它会监听通过 UDP 发送的 span,并发送到收集程序。这个代理应被放置在要管理的应用程序的同一主机上。这通常是通过如 Kubernetes 等容器环境中的 sidecar 来实现的。
- Jaeger Collector : 与代理类似,该收集器可以接收 span,并将其放入内部队列以便进行处理。这允许收集器立即返回到客户端/代理,而不需要等待 span 进入存储。
- Storage : 收集器需要一个持久的存储后端。Jaeger 带有一个可插入的机制用于 span 存储。
- Query : Query 是一个从存储中检索 trace 的服务。
- Ingester : 可选组件。Jaeger 可以使用 Apache Kafka 作为收集器和实际后备存储之间的缓冲。Ingester 是一个从 Kafka 读取数据并写入另一个存储后端的服务。
- Jaeger UI : Jaeger 提供了一个用户界面,可让您可视觉地查看所分发的追踪数据。在搜索页面中,您可以查找 trace,并查看组成一个独立 trace 的 span 详情。
本地环境部署
主要是偏重使用 all-in-one 方式
docker 部署
docker run -d --name jaeger \
-e COLLECTOR_ZIPKIN_HOST_PORT=:9411 \
-p 5775:5775/udp \
-p 6831:6831/udp \
-p 6832:6832/udp \
-p 5778:5778 \
-p 16686:16686 \
-p 14268:14268 \
-p 14250:14250 \
-p 9411:9411 \
jaegertracing/all-in-one:latest
k8s方式(Jaeger Operator)
apiVersion: jaegertracing.io/v1
kind: Jaeger
metadata:
name: local-jaeger
spec:
strategy: allInOne # 部署策略
allInOne:
image: jaegertracing/all-in-one:latest
options:
log-level: debug # 日志等级
storage:
type: memory # 可选 Cassandra、Elasticsearch
options:
memory:
max-traces: 100000
ingress:
enabled: false
agent:
strategy: sidecar # 代理部署策略可选 DaemonSet
query:
serviceType: NodePort # 用户界面使用 NodePort
测试环境部署
docker-compose部署
version: "3"
services:
zookeeper:
image: 'bitnami/zookeeper:latest'
ports:
- '2181:2181'
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
networks:
- jaeger
kafka:
image: 'bitnami/kafka:latest'
ports:
- '9092:9092'
environment:
- KAFKA_BROKER_ID=1
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://10.10.10.10:9092
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR=1
- ALLOW_PLAINTEXT_LISTENER=yes
depends_on:
- zookeeper
networks:
- jaeger
collector:
container_name: jaeger-collector
image: 'jaegertracing/jaeger-collector:latest'
ports:
- '9411:9411'
- '14250:14250'
- '14268:14268'
- '14269:14269'
environment:
- SPAN_STORAGE_TYPE=kafka
- KAFKA_PRODUCER_BROKERS=kafka:9092
- KAFKA_PRODUCER_TOPIC=tracing_jaeger_span_test
- LOG_LEVEL=debug
networks:
- jaeger
agent:
image: 'jaegertracing/jaeger-agent:latest'
ports:
- '5775:5775/udp'
- '6831:6831/udp'
- '6832:6832/udp'
- '5778:5778'
environment:
- REPORTER_GRPC_HOST_PORT=collector:14250
- LOG_LEVEL=debug
depends_on:
- jaeger-collector
networks:
- jaeger
query:
container_name: jaeger-query
image: 'jaegertracing/jaeger-query:latest'
ports:
- '16686:16686'
- '16687:16687'
environment:
- SPAN_STORAGE_TYPE=elasticsearch
- ES_SERVER_URLS=10.10.10.20:9090 # es地址
- LOG_LEVEL=debug
networks:
- jaeger
ingester:
container_name: jaeger-ingester
image: 'jaegertracing/jaeger-ingester:latest'
ports:
- '14270:14270'
environment:
- SPAN_STORAGE_TYPE=elasticsearch
- ES_SERVER_URLS=10.10.10.20:9090
- LOG_LEVEL=debug
networks:
- jaeger
entrypoint: ["/go/bin/ingester-linux", '--kafka.consumer.brokers=kafka:9092', '--kafka.consumer.topic=tracing_jaeger_span_test']
networks:
jaeger:
线上环境部署
以下均使用k8s方式部署
部署 Jaeger Operator
原生方式
kubectl create namespace observability # <1>
kubectl create -f https://raw.githubusercontent.com/jaegertracing/jaeger-operator/master/deploy/crds/jaegertracing.io_jaegers_crd.yaml # <2>
kubectl create -n observability -f https://raw.githubusercontent.com/jaegertracing/jaeger-operator/master/deploy/service_account.yaml
kubectl create -n observability -f https://raw.githubusercontent.com/jaegertracing/jaeger-operator/master/deploy/role.yaml
kubectl create -n observability -f https://raw.githubusercontent.com/jaegertracing/jaeger-operator/master/deploy/role_binding.yaml
kubectl create -n observability -f https://raw.githubusercontent.com/jaegertracing/jaeger-operator/master/deploy/operator.yaml
kubectl create -f https://raw.githubusercontent.com/jaegertracing/jaeger-operator/master/deploy/cluster_role.yaml
kubectl create -f https://raw.githubusercontent.com/jaegertracing/jaeger-operator/master/deploy/cluster_role_binding.yaml
Helm 方式
helm install jaeger-operator jaegertracing/jaeger-operator --version=2.25.0 -f jaeger-operator-prod.yaml
jaeger-operator-prod 本身的资源配置
resources:
limits:
cpu: 100m
memory: 128Mi
requests:
cpu: 100m
memory: 128Mi
部署 jaeger
kubectl apply -f jaeger-prod.yaml
jaeger-prod.yaml 内容如下
apiVersion: jaegertracing.io/v1
kind: Jaeger
metadata:
name: tracing-jaeger-prod
spec:
strategy: streaming
storage:
type: elasticsearch
options:
es:
server-urls: http://elasticsearch:9200
username: ES_JAEGER_USER
password: PASSWORD
use-aliases: true
index-prefix: tracing-jaeger
# 当 use-aliases 为 true, 会开启两个cronjob: esRollover esLookback
# 这里需要注意下版本,有些版本使用的是es6的操作语法,而本身使用的是es7的话会有一些问题
# cronjob
esIndexCleaner:
enabled: true
numberOfDays: 7
schedule: "55 23 * * *"
# cronjob
esRollover:
conditions: "{\"max_age\": \"1d\"}"
readTTL: 120h
schedule: "55 23 * * *"
# 需要部署spark,供spark使用
dependencies:
enabled: true
schedule: "55 23 * * *"
sparkMaster:
resources:
requests:
memory: 4096Mi
limits:
memory: 4096Mi
query:
options:
es:
# 使用别名进行查询
use-aliases: true
dependencies:
menuEnabled: true
# 可以自定义菜单
menu: []
agent:
resources:
limits:
cpu: 100m
memory: 128Mi
requests:
cpu: 100m
memory: 128Mi
collector:
maxReplicas: 3
resources:
limits:
cpu: 200m
memory: 256Mi
options:
kafka:
producer:
# 检查 kafka配置 auto.create.topics.enable 是否为true
# 如果为false 需要手动新建topic,否则会报错
topic: tracing-jaeger-spans
brokers: kafka1:9092,kafka2:9092,kafka3:9092
ingester:
maxReplicas: 3
resources:
limits:
cpu: 300m
memory: 512Mi
options:
kafka:
consumer:
topic: tracing-jaeger-spans
brokers: kafka1:9092,kafka2:9092,kafka3:9092
# 消费者协程数,默认1000
numRoutines: 1000